rvest 爬取静态网页
打开一个目标网页,右键查看网页源代码可以在 HTML 结构中原原本本地看到想要抓取的数据,这就是静态网页。 对于静态网页, rvest 包提供了一套简洁和完整的数据抓取方案,主要函数:
- read_html(): 下载并解析网页
- html_elements(): 提取节点元素信息
- html_text2(): 提取节点文本信息
- html_attr(): 提取节点的属性信息, 比如链接
- html_table(): 提取表格代码转化成数据框
另外,爬虫往往都是批量爬取若干网页,这就涉及循环迭代;对提取的文本数 据做进一步的解析和提取,这就涉及正则表达式。
案例:爬取链家网站的数据
搜索并打开目标网页https://wh.lianjia.com/ershoufang/rs%E6%B1%9F%E5%B2%B8%E5%8C%BA/, 先观察网页规律以构建要批量爬取的网址。总共 100多页,这是首页,依次点开第 2,3,…页观察网址规律,有规律就能构造。
先爬取第一页数据
批量提取想要的内容并保存为数据框
这步是爬虫的最关键步骤:从 HTML 源码结构中找到相应位置、提取并保存想要的内容。只要对 HTML 有一点点粗浅了解,再结合浏览器插件SelectorGadget 就足够。
library(rvest)
library(tidyverse)
url = "https://wh.lianjia.com/ershoufang/rs%E6%B1%9F%E5%B2%B8%E5%8C%BA/"
html = read_html(url)
## 房屋名字
# 右下角 CSS 选择器显示内容.title a 就是我们想要提取的书名所对应的节点
title = html |> html_elements(".title a") |> html_text2()
title = title[-length(title)]
head(title)
[1] "老证 自住 精装修,全屋家具家电,可拎包入住"
[2] "满五唯一,南北三房,中高楼层,诚心卖。"
[3] "幸福人家花园洋房复式 空中大别墅 大露台 精装修"
[4] "龙湖天街旁 双地铁 3房1厅 看房方便 老证"
[5] "老证税费低,看房比较方便,自住装修,没抵押产权清晰"
[6] "业主自住精装修 老证 高楼层 采光视野好 诚心卖"
同样的操作,分别对 “小区名”、 “区域”、 “总价”、 “单价” 、“房屋信息”进行识别、提取、存放为向量,再打包到数据框。
该过程是需要逐个调试的,提取的文本内容可能需要做简单的字符串处
理和解析成数值等。
## 小区名
community = html |> html_elements(".positionIcon+ a") |> html_text2()
# 区域
area = html |> html_elements(".positionInfo a+ a") |> html_text2()
# 总价
totalPrice = html |> html_elements(".totalPrice2 span") |> html_text2()
# 单价
unitPrice = html |> html_elements(".unitPrice span") |> html_text2()
# 房屋信息
houseInfo = html |> html_elements(".houseInfo") |> html_text2()
房屋信息数据比较复杂,需要进一步提取:
[1] "3室1厅 | 88.96平米 | 南 | 精装 | 低楼层(共32层) | 2015年建 | 板楼"
[2] "3室1厅 | 90.21平米 | 南 北 | 简装 | 中楼层(共11层) | 2008年建 | 板楼"
[3] "6室3厅 | 197.56平米 | 南 北 | 精装 | 高楼层(共4层) | 2006年建 | 板楼"
[4] "3室1厅 | 91.84平米 | 南 | 精装 | 中楼层(共42层) | 2016年建 | 板楼"
[5] "2室1厅 | 91.82平米 | 南 北 | 精装 | 低楼层(共17层) | 2013年建 | 板塔结合"
[6] "3室1厅 | 87.66平米 | 南 北 | 精装 | 高楼层(共34层) | 2017年建 | 板塔结合"
strsplit(houseInfo[1], " | ", fixed = TRUE) |> unlist()
[1] "3室1厅" "88.96平米" "南" "精装"
[5] "低楼层(共32层)" "2015年建" "板楼"
讲提取的信息封装成函数,再map_dfr组成数据框。
houseInfo_fmt = function(house){
temp = strsplit(house, " | ", fixed = TRUE) |> unlist()
tibble(结构 = temp[1],
面积 = temp[2],
朝向 = temp[3],
装修 = temp[4],
楼层 = temp[5],
时间 = temp[6],
类型 = temp[7])
}
houseInfo_fmt(houseInfo[[1]])
# A tibble: 1 × 7
结构 面积 朝向 装修 楼层 时间 类型
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 3室1厅 88.96平米 南 精装 低楼层(共32层) 2015年建 板楼
houseInfo_df = map_dfr(houseInfo, houseInfo_fmt)
knitr::kable(head(houseInfo_df))
| 3室1厅 |
88.96平米 |
南 |
精装 |
低楼层(共32层) |
2015年建 |
板楼 |
| 3室1厅 |
90.21平米 |
南 北 |
简装 |
中楼层(共11层) |
2008年建 |
板楼 |
| 6室3厅 |
197.56平米 |
南 北 |
精装 |
高楼层(共4层) |
2006年建 |
板楼 |
| 3室1厅 |
91.84平米 |
南 |
精装 |
中楼层(共42层) |
2016年建 |
板楼 |
| 2室1厅 |
91.82平米 |
南 北 |
精装 |
低楼层(共17层) |
2013年建 |
板塔结合 |
| 3室1厅 |
87.66平米 |
南 北 |
精装 |
高楼层(共34层) |
2017年建 |
板塔结合 |
再将小区名、总价、单价等新组合在一起
df = cbind(title,community,area,totalPrice,unitPrice,houseInfo_df)
knitr::kable(head(df))
| 老证 自住 精装修,全屋家具家电,可拎包入住 |
汉口城市广场五期 |
后湖 |
190 |
21,358元/平 |
3室1厅 |
88.96平米 |
南 |
精装 |
低楼层(共32层) |
2015年建 |
板楼 |
| 满五唯一,南北三房,中高楼层,诚心卖。 |
景兰苑 |
百步亭 |
128 |
14,190元/平 |
3室1厅 |
90.21平米 |
南 北 |
简装 |
中楼层(共11层) |
2008年建 |
板楼 |
| 幸福人家花园洋房复式 空中大别墅 大露台 精装修 |
幸福人家北苑 |
后湖 |
338 |
17,109元/平 |
6室3厅 |
197.56平米 |
南 北 |
精装 |
高楼层(共4层) |
2006年建 |
板楼 |
| 龙湖天街旁 双地铁 3房1厅 看房方便 老证 |
福星惠誉红桥城 |
堤角 |
156.8 |
17,074元/平 |
3室1厅 |
91.84平米 |
南 |
精装 |
中楼层(共42层) |
2016年建 |
板楼 |
| 老证税费低,看房比较方便,自住装修,没抵押产权清晰 |
鼎盛华城 |
后湖 |
165 |
17,970元/平 |
2室1厅 |
91.82平米 |
南 北 |
精装 |
低楼层(共17层) |
2013年建 |
板塔结合 |
| 业主自住精装修 老证 高楼层 采光视野好 诚心卖 |
百步亭金桥汇II期 |
塔子湖 |
156 |
17,797元/平 |
3室1厅 |
87.66平米 |
南 北 |
精装 |
高楼层(共34层) |
2017年建 |
板塔结合 |
批量提取
把从一个网页提取保存各个内容到保存为数据框的过程,定义为函数:
get_html = function(html){
title = html |> html_elements(".title a") |> html_text2()
title = title[-length(title)]
## 小区名
community = html |> html_elements(".positionIcon+ a") |> html_text2()
# 区域
area = html |> html_elements(".positionInfo a+ a") |> html_text2()
# 总价
totalPrice = html |> html_elements(".totalPrice2 span") |> html_text2()
# 单价
unitPrice = html |> html_elements(".unitPrice span") |> html_text2()
# 房屋信息
houseInfo = html |> html_elements(".houseInfo") |> html_text2()
strsplit(houseInfo, " | ")[[1]]
houseInfo_fmt = function(house){
temp = strsplit(house, " | ", fixed = TRUE)|> unlist()
tibble(结构 = temp[1],
面积 = temp[2],
朝向 = temp[3],
装修 = temp[4],
楼层 = temp[5],
时间 = temp[6],
类型 = temp[7])
}
houseInfo_fmt(houseInfo[[1]])
houseInfo_df = map_dfr(houseInfo, houseInfo_fmt)
cbind(title,community,area,totalPrice,unitPrice,houseInfo_df)
}
批量下载并解析这5个网页,用 map 循环迭代依次将read_html()作用在每个网址上。
但是直接这样做(同一IP瞬间打开5个网页)太容易触发网站的反爬虫机制,最简单(反爬机制稍强就会失效)的做法是增加一个随机等待时间:
library(rvest)
library(tidyverse)
read_url = function(url){
# Sys.sleep(sample(3,1)) # 休眠随机 1~3 秒
read_html(url)
}
content = "江岸区"
urls = str_c("https://wh.lianjia.com/ershoufang/jiangan/pg",1:5,"rs",content,"/")
htmls = map(urls, read_url)
然后用map_dfr依次将该函数应用到每个网页同时按行合并到一个结果数据框:
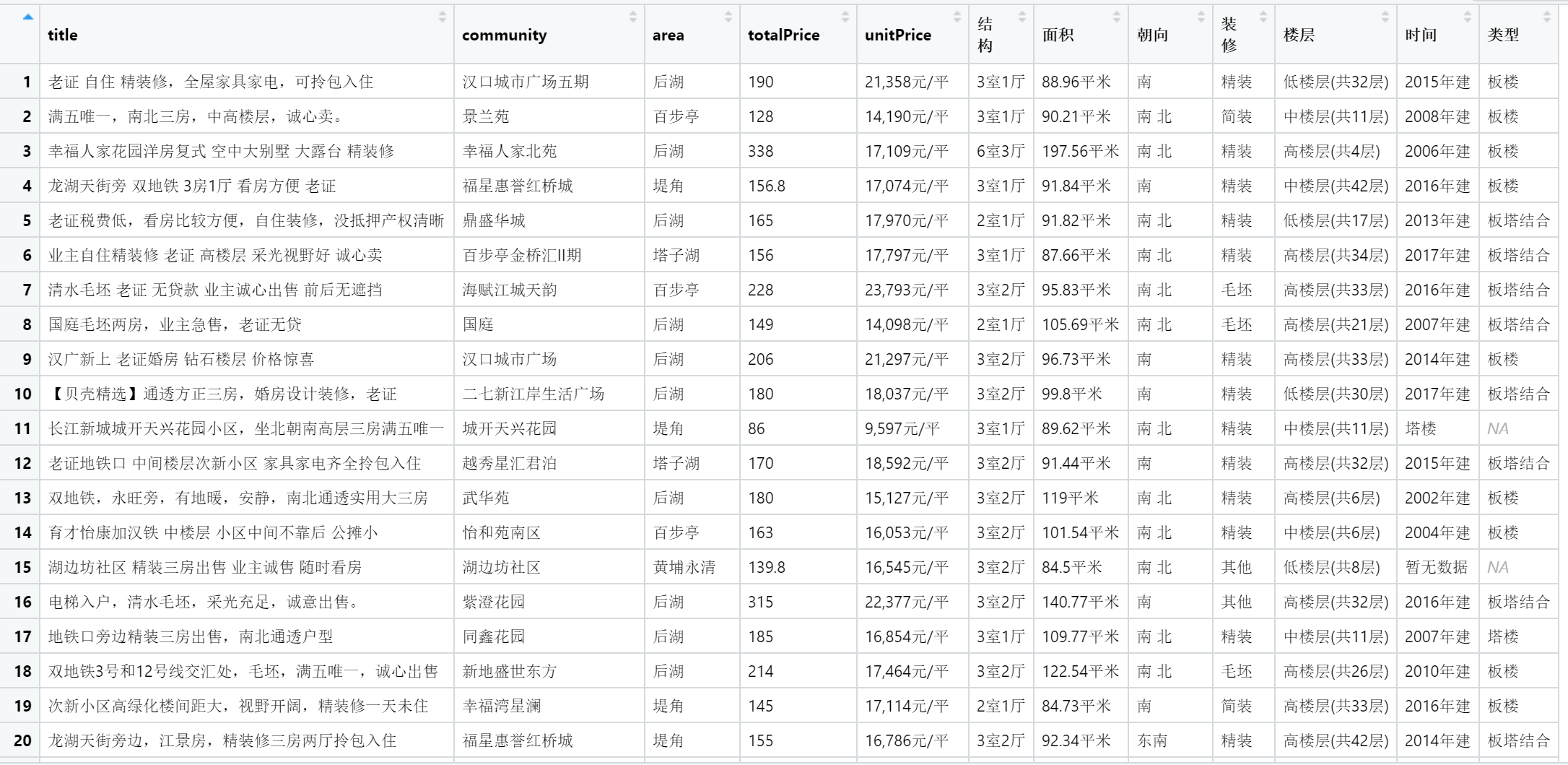
lianjia_df = map_dfr(htmls, get_html)
这就将 150 项房屋信息都爬取下来,并保存在一个数据框(部分):
鄂ICP备2022016232号-1