模拟登录
很多爬取的网页是需要先登录的,所以需要在爬取网页数据之前模拟登录,然后进行数据的爬取。 模拟登录的网址为:
https://www.cctry.com/member.php?mod=logging&action=login
模拟登录的第一步是模拟对话。通过 session( ) 函数模拟与服务器的会话,然后使 用 html_form( ) 来解析网页的表单,希望从中找到 username 和 password 的数据位置。
library (rvest)# 取地址,用session模拟会话 <- 'https://www.cctry.com/member.php?mod=logging&action=login' <- session (url)
<session> https://www.cctry.com/member.php?mod=logging&action=login
Status: 200
Type: text/html; charset=gbk
Size: 18352
# 使用html_form 来解析网页的表单 <- html_form (pgsession) # 在这里找,列表的第几个元素包含了username、password
[[1]]
<form> 'scbar_form' (POST https://www.cctry.com/search.php?searchsubmit=yes)
<field> (hidden) mod: search
<field> (hidden) formhash: 7bb16c45
<field> (hidden) srchtype: title
<field> (hidden) srhfid: 0
<field> (hidden) srhlocality: member::logging
<field> (text) srchtxt: 请输入搜索内容
<field> (button) searchsubmit: true
[[2]]
<form> 'loginform_LO31n' (POST https://www.cctry.com/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LO31n)
<field> (hidden) formhash: 7bb16c45
<field> (hidden) referer: https://www.cctry...
<field> (text) username:
<field> (password) password:
<field> (select) questionid:
<field> (text) answer:
<field> (checkbox) cookietime: 2592000
<field> (button) loginsubmit: true
[[3]]
<form> 'lostpwform_LO31n' (POST https://www.cctry.com/member.php?mod=lostpasswd&lostpwsubmit=yes&infloat=yes)
<field> (hidden) formhash: 7bb16c45
<field> (hidden) handlekey: lostpwform
<field> (text) email:
<field> (text) username:
<field> (button) lostpwsubmit: true
<- pgform[[2 ]] # 这里提取对应的列表,第二个
在上面一步的代码中,使用 session( )传入需要登录的页面,然后使用 html_form ( ) 解析网页的表单,再在解析的表单中找到 username、password 在解析结果列表中的位置,最 后提取对应列表的解析结果。这样做的目的是找到填写账号、密码的表单。如上面的结果 所示,账号、密码对应着第三个列表。 接下来填写账号与密码。使用 html_form_set( )来填写表单中的账号、密码,然后通过 session_submit( )进行提交。
<- html_form_set (pgform1,'username' = 'aaaaa@qq.com' ,'password' = '1111111' )
<- session_submit (pgsession, filled_form)
<session> https://www.cctry.com/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=LO31n
Status: 200
Type: text/html; charset=gbk
Size: 18926
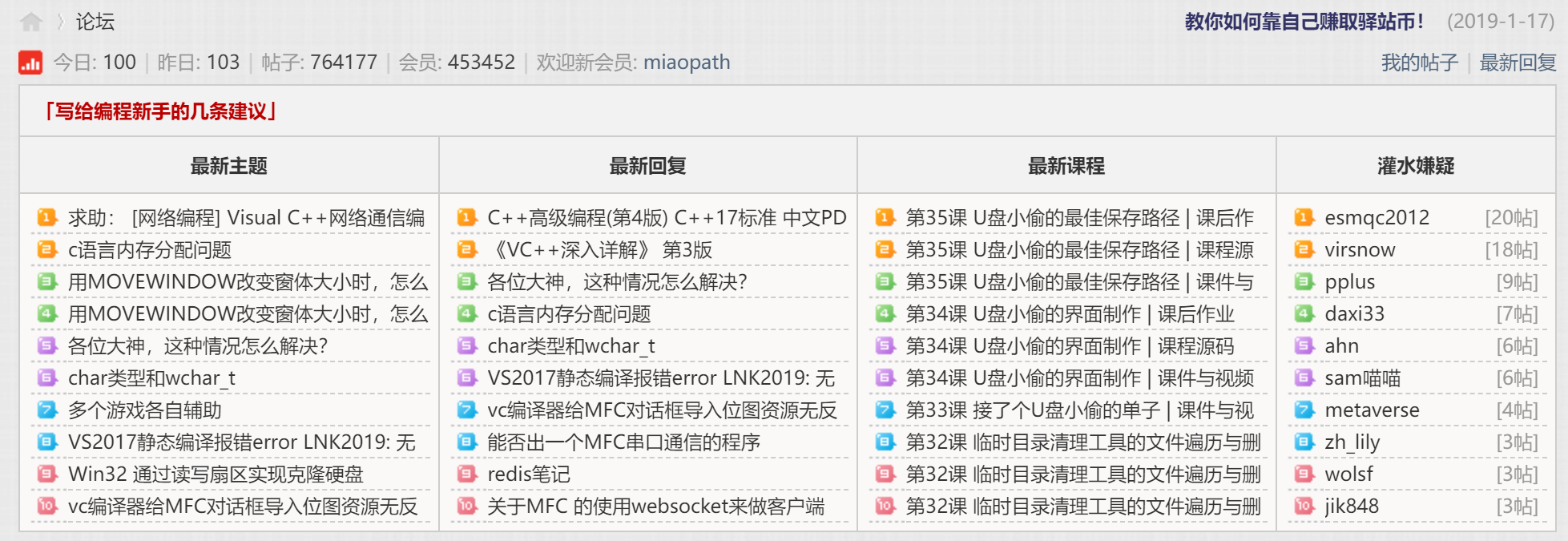
# 登录成功后跳转到首页,即可爬取网页。 = "https://www.cctry.com" |> session_jump_to (url2) |> html_elements ("td:nth-child(1) .threadline_7ree a" ) |> html_text2 ()
[1] "求助: [网络编程] Visual C++网络通信编程技术详解 带书签 高 ..."
[2] "c语言内存分配问题"
[3] "用MOVEWINDOW改变窗体大小时,怎么才能做到窗体图片不闪动?"
[4] "用MOVEWINDOW改变窗体大小时,怎么才能做到窗体图片不闪动?"
[5] "各位大神,这种情况怎么解决?"
[6] "char类型和wchar_t"
[7] "多个游戏各自辅助"
[8] "VS2017静态编译报错error LNK2019: 无法解析的外部符号 __imp__x ..."
[9] "Win32 通过读写扇区实现克隆硬盘"
[10] "vc编译器给MFC对话框导入位图资源无反应"
这样,就完成了登录的模型,并可以进一步爬取数据。
网络是获取数据的一个重要渠道,但是如果想要获取网页中的数据,那么就必须掌握爬虫这门工具,以便从网页中爬取数据。虽然 R 语言是进行数据分析的优秀工具,但是 R 语言并不是专业开发爬虫软件的工具,这并不妨碍使用 R 语言编写爬虫代码、爬取数据。 当需要快速爬取网页数据,并进行分析时,R 语言是一个非常好的选择。使用 R 语言能够 非常快速地完成爬虫和数据分析的工作。本文章介绍了如何使用 R 语言爬取网络数据,如何 爬取多网页的数据,以及行为模拟。当然,很多关于爬虫的内容在本章没有涉及,但是对于想要快速爬取数据的 R 用户而言,这些已经足够了,因为绝大部分情况下可以使用这样 的方式来获取网页数据。
鄂ICP备2022016232号-1