library(httr)
library(tidyverse)
## 构造请求头
myCookie = 'NTESSTUDYSI=27d5bed675e8438fb988225e40ecab95; EDUWEBDEVICE=fd132bb567f54ddf9972bb0175ca8067; EDU-YKT-MODULE_GLOBAL_PRIVACY_DIALOG=true; STUDY_SESS="aTdDjhQ54AZuSIGmfvEAO0oq1MntB6KLMlfckHJ2wJnpR7IiLOKFeshAT2UmJlkuWn/+7Zi/dVHMMwi9yi6vsst9a0bJTb8Jgx7AJR+jSpJAxhWPTh0ICwJN2wzuf98hqXldXNC0KNVbktOjRvcj/j8e9GuD3WINy3FjlDEn47FvDqMeYnnV6e/9fyZ0VYCh+P6MxCmnJEvne6pPMc9TTJJnThNrM7aj0X5LVpSBvja1h64TEIxycg2vUqLMpdsCc4/5ihwJAOSorVYu6ct68aqXWOYgvMG4QZKP4MISyzxKlOh/Gwx6G1S/X4FQ7qd/6S4rEsGoBH45IxB7lK+bLEhxIaqlPImqp3Lcnj4Le48EPT29EbzDyDxX4vNTTFN+"; STUDY_INFO="UID_33C7969AE23D7565BEB97F076F07EF71|4|1144234087|1667180444900"; DICT_SESS=v2|c7b9qt-w-WJBOMPBh4Qy0kAhMez64gLRqF0fOMP46B0Q40H6FkLOG0pz64YA6MeBRwyRMUm6LwuROEPMkm0MqZ0PK6Lq40M640; DICT_LOGIN=1||1667180445126; NETEASE_WDA_UID=1144234087#|#1534823950610; NTES_STUDY_YUNXIN_ACCID=s-1144234087; NTES_STUDY_YUNXIN_TOKEN=c2a417486a5b31eaee6c3e46a366ff8e; utm=eyJjIjoiIiwiY3QiOiIiLCJpIjoiIiwibSI6IiIsInMiOiIiLCJ0IjoiIn0=|aHR0cHM6Ly9zdHVkeS4xNjMuY29tL2NhdGVnb3J5LzQ4MDAwMDAwMzEzMTAwOT9mcm9tPXN0dWR5; sideBarPost=2181; STUDY_UUID=71f0da48-9ecc-49a8-bb53-dc8b94cc0340'
myUserAgent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
headers = c('accept' = 'application/json',
'edu-script-token' = '27d5bed675e8438fb988225e40ecab95',
'User-Agent' = myUserAgent,
'cookie' = myCookie)
# 二次实际请求到的 url
url = "https://study.163.com/p/search/studycourse.json"
# 构造请求 Payload
payload = list('pageIndex' = 1, 'pageSize' = 50,
'relativeOffset' = 0, 'frontCategoryId' = "400000001334002")动态网页,是基于 AJAX(异步 JavaScript 和 XML)技术动态加载内容,浏览到的内容是由服务器端根据时间、环境或数据库操作结果而动态生成,直接查看网页源码是看不到想要爬取的信息的。爬取动态网页就需要先发送请求,对请求到的结果再做解析、提取、保存,rvest 包就无能为力了。 RCurl 包或者其简化版的 httr 包可以爬取动态网页。
今天呢,主要介绍httr包,虽然说这个R包已经比RCurl精简很多,但涉及到的函数也很多,但是常规爬虫中用的比较多的还是GET和POST这两个函数。
下文案例是个典型的POST请求类的爬虫,因此,今天先看下POST这个函数的大致用法:POST(url = NULL, config = list(), ..., body = NULL, encode = c(“multipart”, “form”, “json”, “raw”), handle = NULL),这里面比较重要的是config参数(设置请求头和cookies)和 body参数(查询参数)。具体参数解释如下:
url :the url of the page to retrieve
config:Additional configuration settings such as http authentication (authenticate), additional headers (add_headers), cookies (set_cookies) etc. See config for full details and list of helpers. Further named parameters, such as query, path, etc, passed on to modify_url. Unnamed parameters will be combined with config.
body:One of the following:
FALSE: No body. This is typically not used with POST, PUT, or PATCH, but can be useful if you need to send a bodyless request (like GET) with VERB().
NULL: An empty body
““: A length 0 body
upload_file(“path/”): The contents of a file. The mime type will be guessed from the extension, or can be supplied explicitly as the second argument to upload_file()
A character or raw vector: sent as is in body. Use content_type to tell the server what sort of data you are sending.
A named list: See details for encode. (比较常用)
encode:If the body is a named list, how should it be encoded? Can be one of form (application/x-www-form-urlencoded), multipart, (multipart/form-data), or json (application/json). For “multipart”, list elements can be strings or objects created by upload_file. For “form”, elements are coerced to strings and escaped, use I() to prevent double-escaping. For “json”, parameters are automatically “unboxed” (i.e. length 1 vectors are converted to scalars). To preserve a length 1 vector as a vector, wrap in I(). For “raw”, either a character or raw vector. You’ll need to make sure to set the content_type() yourself.
handle:The handle to use with this request. If not supplied, will be retrieved and reused from the handle_pool based on the scheme, hostname and port of the url. By default httr requests to the same scheme/host/port combo. This substantially reduces connection time, and ensures that cookies are maintained over multiple requests to the same host. See handle_pool for more details.
为了更好理解httr:POST这个函数如何抓取动态异步加载网页,下面以网易云课程为例做简单介绍!
案例:爬取网易云课堂编程与开发类课程
找到要爬取的内容
打开网易云课堂, 登录账号,选择编程与开发,进入目标页面 https://study.163.com/category/400000001334002。 右键 “检查”,依次点击 “Network”, “fetch/HXR”,刷新网页,则右下窗口出现很多内容,浏览找到 studycourse.json, 点开,在 preview 下可以找到想要抓取的内容:
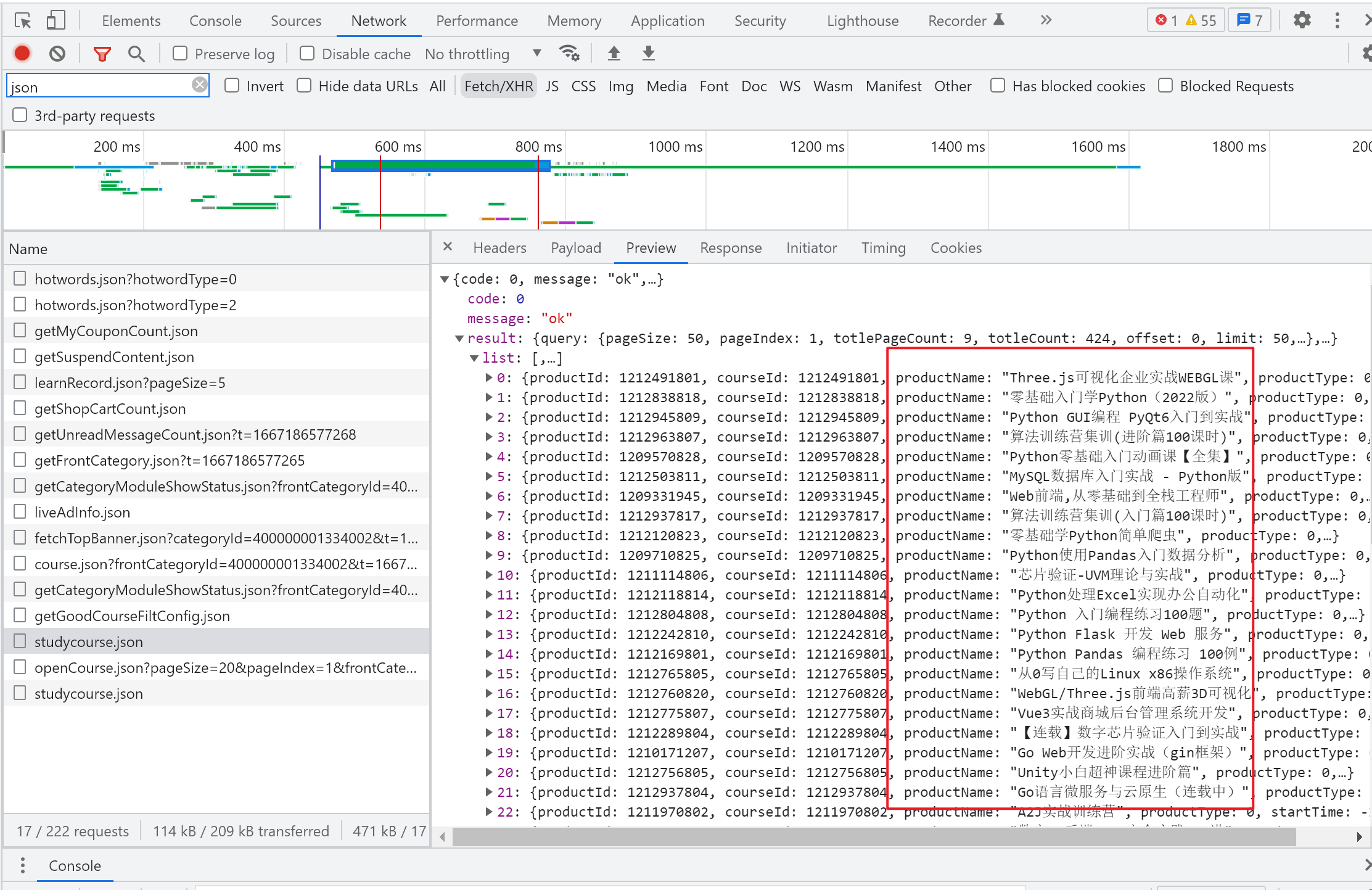
在正式爬取之前,需要对下面爬虫主要涉及的参数做下介绍:General里面的Request URL、Request Method、Status Code;Response Headers里面的Content-Type;Request Headers 里面的 Accept、Content-Type、Cookie、Referer、User-Agent等以及最后Form data/Request Paylond里面的所有参数。
General里面的Request URL和Request Method方法即是即决定访问的资源对象和使用的技术手段。
Response Headers里面的Content-Type决定着你获得的数据以什么样的编码格式返回。
Request Headers 里面的 Accept、Content-Type、Cookie、Referer、User-Agent等是你客户端的浏览器信息,其中Cookie是你浏览器登录后缓存在本地的登录状态信息,使用Cookie登入可以避免爬虫程序被频繁拒绝。这其中的参数不一定全部需要提交。
Form data/Request Payload信息最为关键,是POST提交请求必备的定位信息,因为浏览器的课程页有很多页信息,但是实际上访问同一个地址(就是General里面的url),而真正起到切换页面的就是这个Form data/Request Payload里面的表单信息。
构造请求 Headers, 用 POST 方法请求网页内容
点开 Headers,
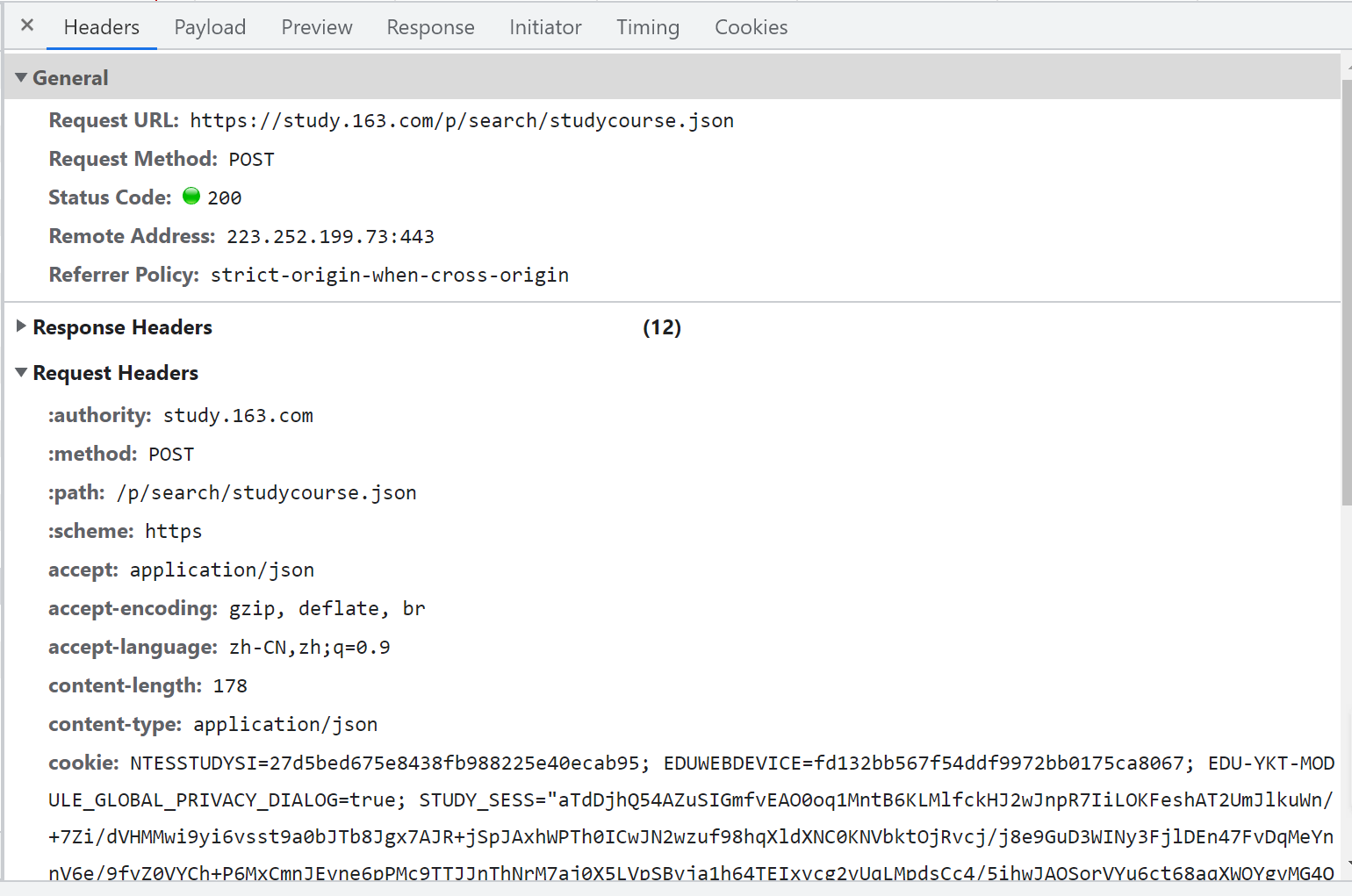
重点关注:
General 下的: Request URL, Request Method, Status Code
Request Headers 下的: accept, edu-script-token,cookie, user-agent
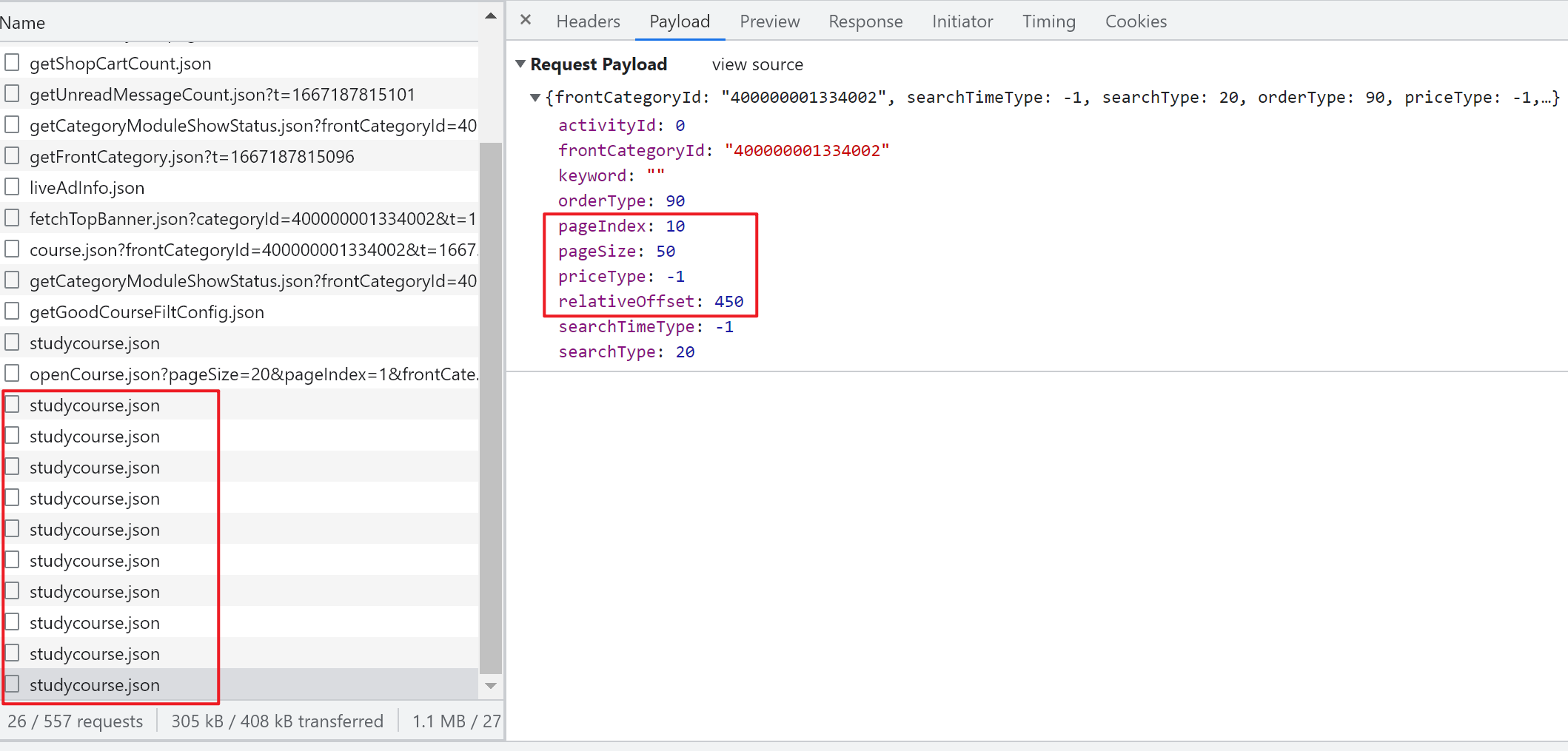
点开Payload
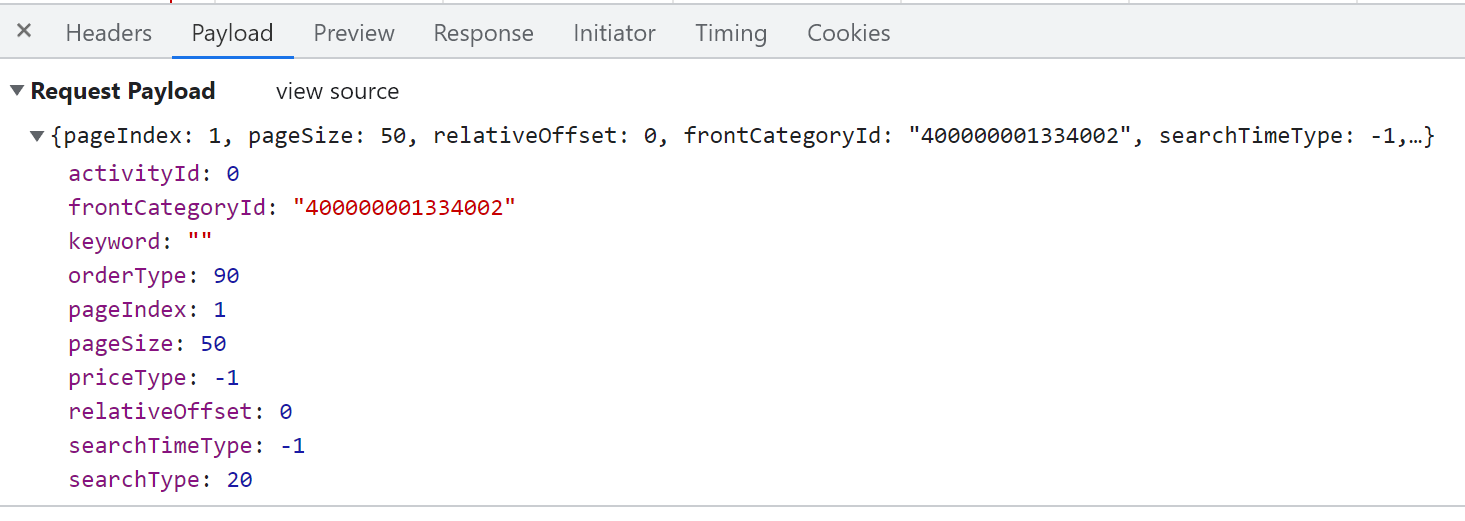
重点关注 Request Payload 下的: pageIndex, pageSize,relativeOffset, rontCategoryId 获取这些信息之后,就可以在 R 中构造 Headers
然后,就可以伪装成浏览器,发送 POST 请求获取数据:
## POST 方法执行单次请求
result = POST(url, add_headers(.headers = headers), body = payload, encode = "json")提取想要的结果
前面爬虫得到的 result 是 json 数据生成的复杂嵌套列表,需要把想要的数据提取出来,并创建成数据框。
批量从一系列相同结构的列表提取某个成分下的内容,非常适合用 map 映射成分名,对于内容为空的,设置参数.null = NA, 以保证数据框各列等长:
# 50 个课程信息列表的列表
lensons = content(result)$result$list
df = tibble(ID = map_chr(lensons, "courseId"),
title = map_chr(lensons, "productName"),
provider = map_chr(lensons, "provider"),
score = map_dbl(lensons, "score"),
learnerCount = map_dbl(lensons, "learnerCount"),
lessonCount = map_dbl(lensons, "lessonCount"),
lector = map_chr(lensons, "lectorName", .null = NA))
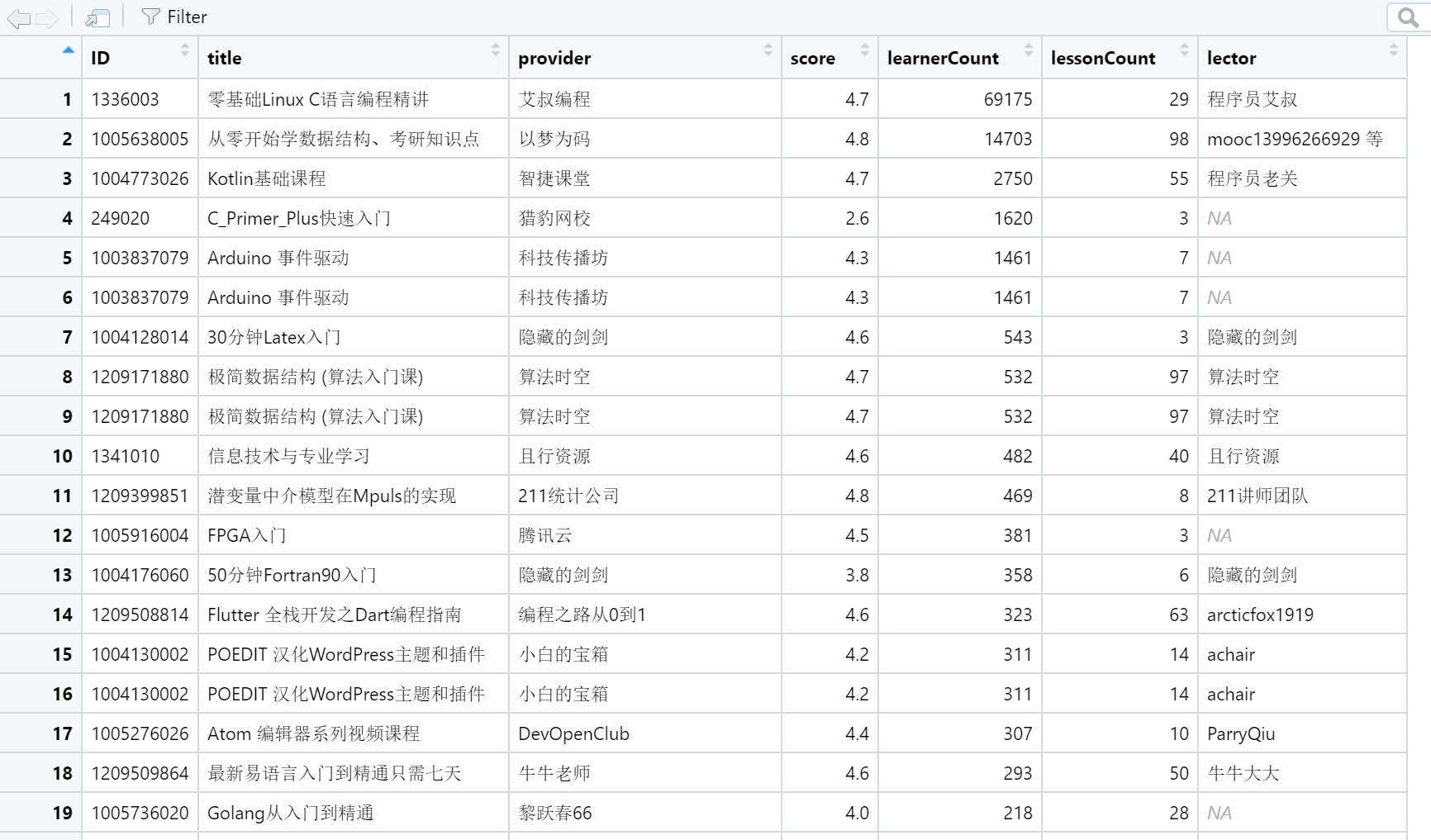
knitr::kable(head(df,10))| ID | title | provider | score | learnerCount | lessonCount | lector |
|---|---|---|---|---|---|---|
| 1209661815 | Visual Basic 2008入门到实战 | 宝满教育培训 | 3.0 | 20 | 108 | NA |
| 1209702803 | JSP入门到精通教程 | 宝满教育培训 | 3.0 | 6 | 55 | NA |
| 249020 | C_Primer_Plus快速入门 | 猎豹网校 | 2.6 | 1620 | 3 | NA |
| 1209666808 | 全套编程开发入门到精通在线课程 | 宝满教育培训 | 4.4 | 4 | 220 | NA |
| 1209677814 | Visual FoxPro 9程序设计课程 | 宝满教育培训 | 4.4 | 18 | 182 | NA |
| 1006186115 | Oracle集群技术 | 沃趣科技 | 4.4 | 0 | 4 | NA |
| 1209698817 | Scratch少儿编程课 | 仙童创客 | 4.2 | 42 | 6 | 童童老师 |
| 1209826849 | Scratch编程等级考试一级 | 小兔子老师 | 4.5 | 51 | 11 | 小兔子老师 |
| 1210029804 | VSCode 全景学习 语言篇 | 守破离编程之道 | 4.4 | 19 | 15 | NA |
| 1209349810 | VSCode 全景学习 基础篇 | 守破离编程之道 | 4.4 | 55 | 11 | yuhao |
批量爬取所有页
这次不同页面是通过修改 Payload 参数实现的,总共 10 页,同样将爬取一 页并保存到数据框过程定义为函数,自变量为第几页的序号:
get_html = function(p) {
Sys.sleep(sample(5, 1))
payload = list('pageIndex' = p, 'pageSize' = 50,
'relativeOffset' = 50*(p-1),
'frontCategoryId' = "480000003131009")
# POST 方法执行单次请求
result = POST(url, add_headers(.headers = headers),
body = payload, encode = "json")
lensons = content(result)$result$list
tibble(
ID = map_chr(lensons, "courseId"),
title = map_chr(lensons, "productName"),
provider = map_chr(lensons, "provider"),
score = map_dbl(lensons, "score"),
learnerCount = map_dbl(lensons, "learnerCount"),
lessonCount = map_dbl(lensons, "lessonCount"),
lector = map_chr(lensons, "lectorName", .null = NA))
}用 map_dfr 依次将该函数应用到每页序号向量,同时按行合并到一个结果数 据框,再根据学习人数递降排序,保存到数据文件:
# 爬3页
wy_lessons = map_dfr(1:3, get_html) %>%
arrange(-learnerCount)
knitr::kable(tail(wy_lessons,10))| ID | title | provider | score | learnerCount | lessonCount | lector |
|---|---|---|---|---|---|---|
| 1209458825 | 带你玩转CSS3的3D炫酷特效 | 跟竹迩一起学Java | 4.4 | 0 | 7 | NA |
| 1212235806 | 深入浅出solidity | 火链教育 | 4.4 | 0 | 83 | NA |
| 1212229801 | VUE框架 | 火链教育 | 4.4 | 0 | 151 | NA |
| 1212169840 | 区块链核心&比特币实战 | 火链教育 | 4.4 | 0 | 70 | NA |
| 1212947824 | 零基础 Scratch 闯关课 | 小黑鱼STEM课堂 | 4.4 | 0 | 7 | NA |
| 1212329803 | FiscoBcos核心开发 | 火链教育 | 4.4 | 0 | 11 | NA |
| 1211347801 | ABB工业机器人高级编程 | 重庆汇博聚程智能科技有限公司 | 4.4 | 0 | 19 | NA |
| 1006186115 | Oracle集群技术 | 沃趣科技 | 4.4 | 0 | 4 | NA |
| 1213004805 | 高清matlab建模预测规划回归分析 | 硬核的野生技术 | 4.4 | 0 | 4 | NA |
| 1209458825 | 带你玩转CSS3的3D炫酷特效 | 跟竹迩一起学Java | 4.4 | 0 | 7 | NA |
# write.csv(wy_lessons, file = "网易云课堂编程开发类课程.csv")爬取的150个课程信息: